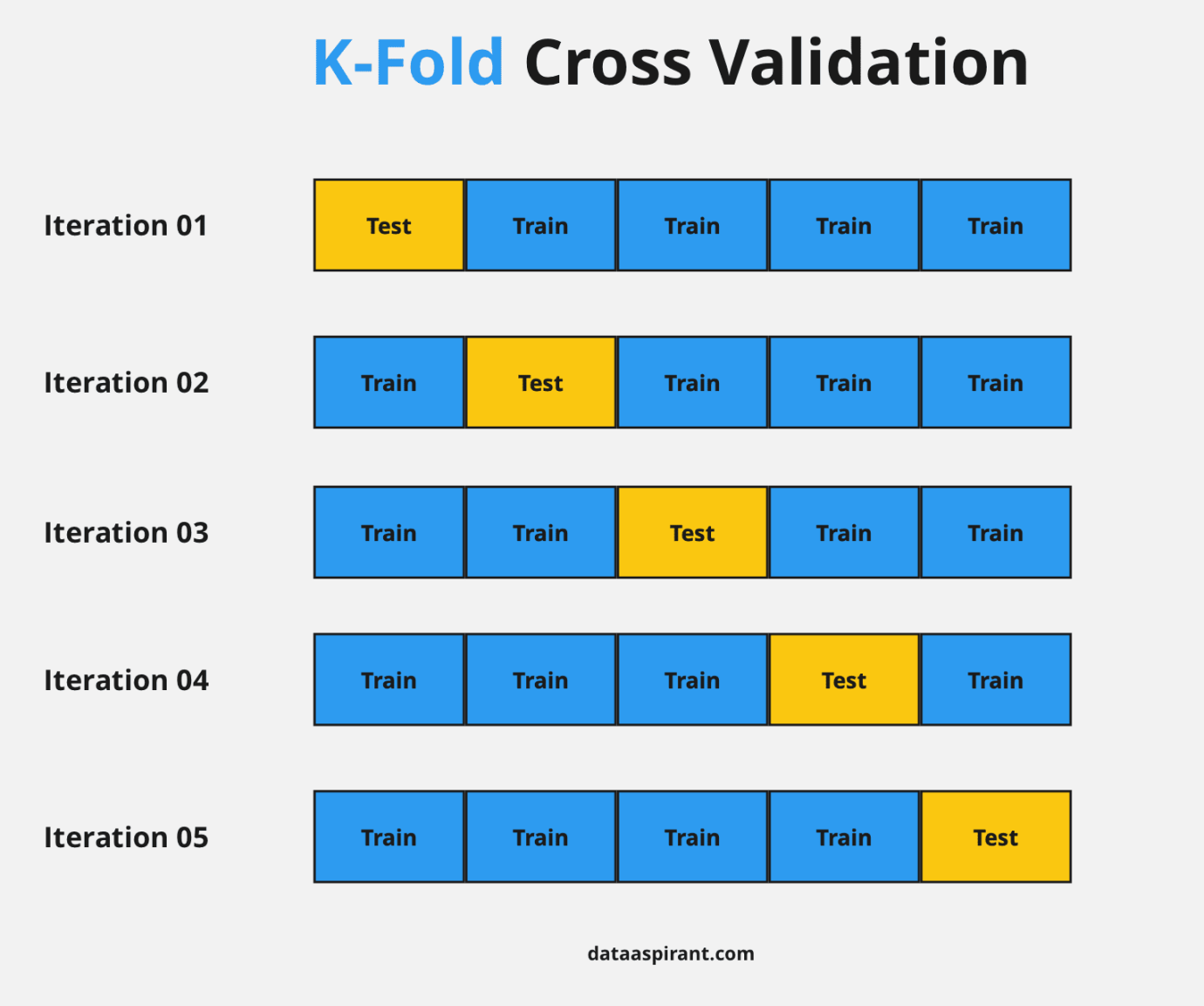
✅ Why is Cross-Validation Needed?
In any machine learning model, if the model performs poorly on the test data, we typically adjust the hyperparameters or switch to a different model. If we repeat this process multiple times, there is a chance that we might achieve good accuracy on the test data without overfitting. However, despite this, the model might still perform poorly on unseen data. The reason for this is that we measured the generalization error multiple times on the test set, causing the model and its hyperparameters to adapt specifically to that set. As a result, the model becomes overly optimized for the test set and is unlikely to perform well on new, unseen data.