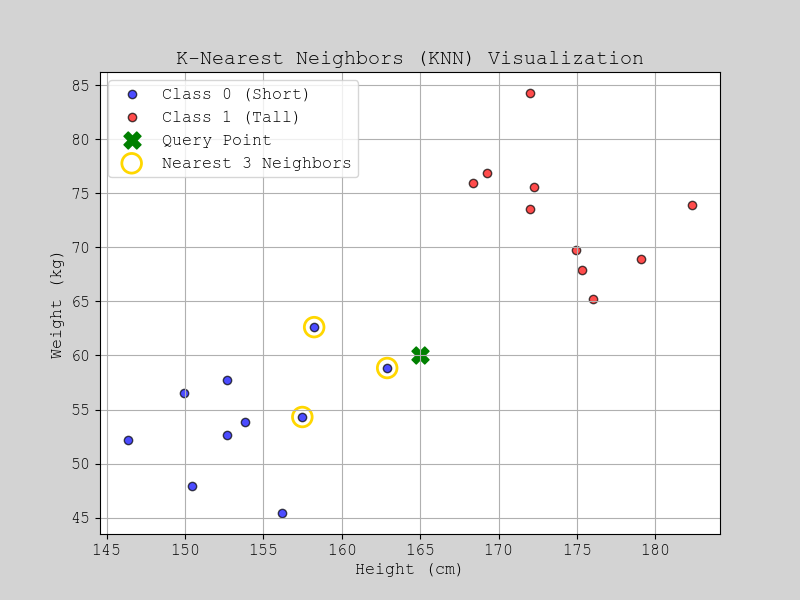
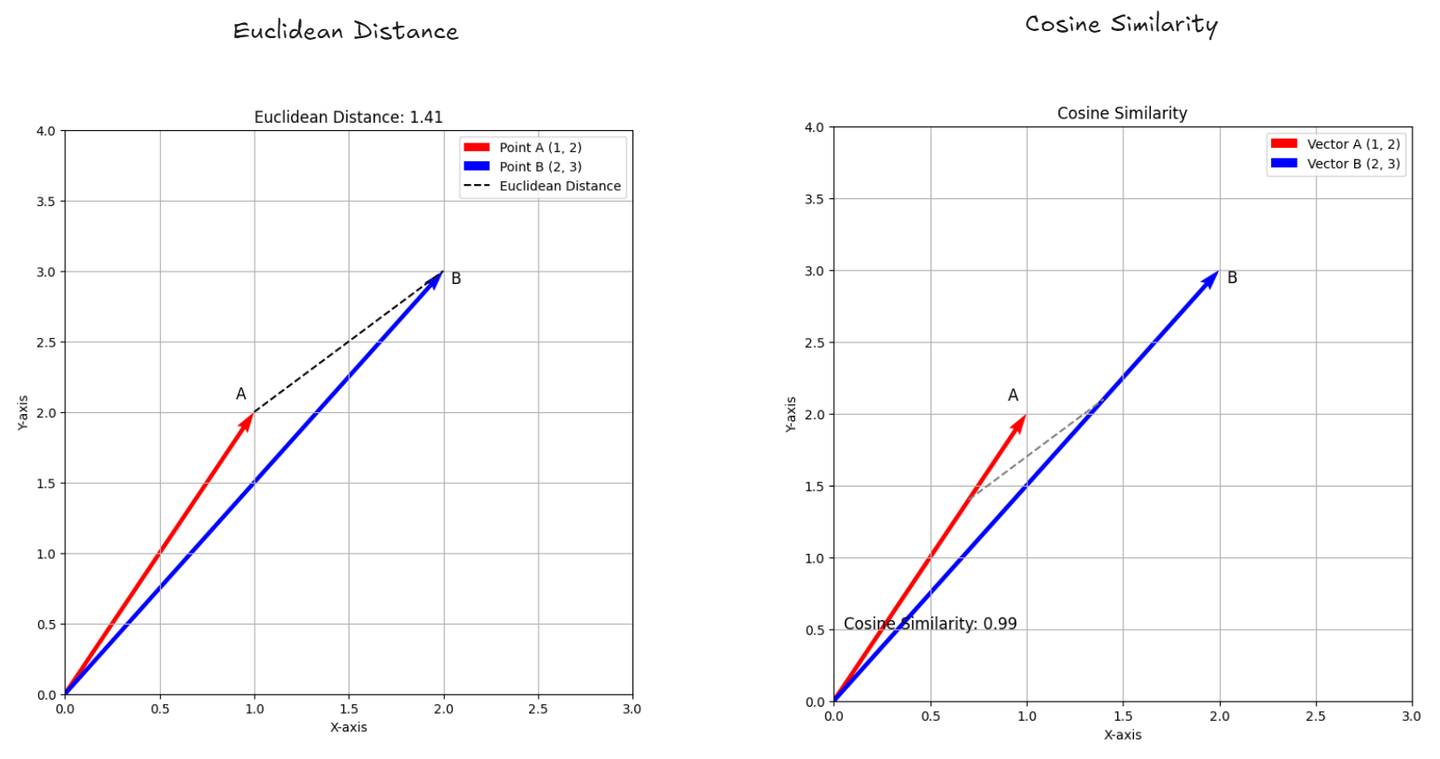
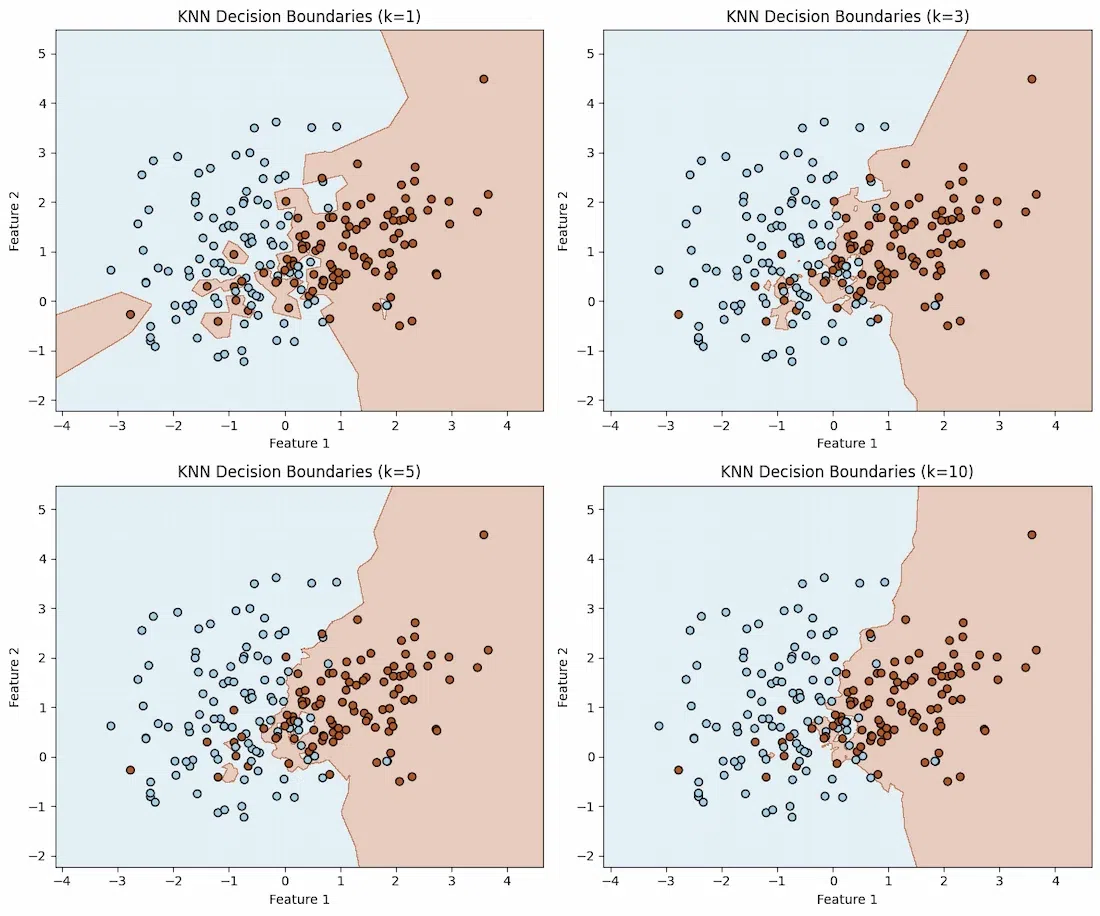
🔹 K = 1 (Overfitting, Very Detailed Boundaries)
- The model follows each individual data point closely.
- The boundary is highly irregular and sensitive to noise.
🔹 K = 3 (Balanced, Smooth but Still Detailed)
- The boundary is still detailed but less sensitive to small variations.
- Less overfitting than K=1.
🔹 K = 5 (Smooth, More Generalized)
- The boundary becomes smoother.
- The model generalizes better but loses some fine details.
🔹 K = 10 (Underfitting, Too Simple)
- The boundary is very smooth and almost linear.
- The model underfits the data and loses key patterns.